(info D2) IA génératives locales
— Introduction
Pourquoi préférer l'usage de modèles génératifs en local, sur son propre poste ou un serveur mutualisé :
- Possibilité de choisir ses modèles ;
- Accès à de nombreux paramètres afin de s'éloigner d'une approche magique et consumériste de la génération ;
- Coût nul en dehors du matériel (pour les modèles open source, ou du moins gratuits). Argument à nuancer au regard du vol de données ;
- Confidentialité (relative puisque les images sont stockées sur le serveur local), mais au moins vis-à-vis des acteurs privés ;
- Pas de transfert de données sur internet via des infrastructures cloud, et donc utilisation possible hors-ligne ;
- Selon les modèles, la source de production délectricité et la fréquence d'usage, le coût écologique est moindre ;
- Possibilité d'intégration simplifiée à des dispositifs plus complexes.
— LLM et chat local
Plusieurs outils permettent d'exécuter des LLM localement, et donc en grande partie remplcer ChatGPT, Cmlude, Mistral, Gemini, etc. En voici 2, faciles à installer et à utiliser : Ollama et LM Studio.
En fonction de la puissance de votre ordinateur (GPU et CPU), vous pourrez exécuter des modèles plus ou moins "performants". La performance d'un modèle est en partie relative au nombre de ses paramètres, généralement indiqué par le nombre 7B ou 20B, qui signifie 7 milliards ou 20 milliards de paramètres. Mais elle dépend aussi de son architecture, de sa spécialisation, etc.
Exemples de modèles utilisable via Ollama ou LM Studio :
- gpt-oss:20b est un modèle généraliste. Il peut traiter des documents textuels mais pas les images.
- gemma3 peut décrire des images
— IA génératives locales pour le traitement du son
Si vous installez Pinokio, vour aurez accès à plusieurs solutions de traitement du son :
- Text to speech, pour expérimenter la génération de parole, notamment à partir de votre voix (avec un risque important de dérive en deepfake audio) ;
- Speech to text très utile pour la transcription ;
- Génération de "musique", sons, boucles ou "morceaux" complets.
En dehors de Pinokio la solution de transcription NoScribe est assez performante : https://github.com/kaixxx/noScribe
— Génération de médias (images, vidéos, sons, 3D)
— Logiciels
Cet article de Tech Tactician publié fin 2024 recense les principaux outils de génération locale d'images, de vidéos et d'objets 3D :
- Automatic1111
- Fooocus
- ComfyUI
- Stable Diffusion WebUI Forge
- EasyDiffusion
- MetaStable
- SwarmUI
- SD.Next
- InvokeAI
- StabilityMatrix
- MochiDiffusion
Ces outils offrent des possiblités de contrôle de la génération, à partir d'un prompt ou d'une image (voire d'un flux vidéo) :
- choix du modèle,
- prompt positif/négatif,
- nombre de steps,
- orientation du modèle par le prompt (CFG Scale ou Classifier Free Guidance),
- taille de sortie (valeurs dépendantes du modèle),
- seed (nombre utilisé pour générer le bruit de départ),
- batch (nombre d'images par génération),
- etc.
Le contrôle peut être renforcé par des fonctionnalités intégrées aux outils ou des plugins :
- Sélecteur de styles qui complètent le prompt avec des précisions relatives au type d'image souhaité.
- Loras, ou petits modèles qui vont changer le modèle de base, en adaptant le style général des images; Il est possible d'entraîner ses propres Loras, à partir de quelques dizaines d'images
- ControlNet, un modèle exécuté en parallèle du modèle de génération.
- Voir aussi refiners, upscalers, etc.
Pour cet atelier nous utiliserons principalement Stable Diffusion Web UI, dédié à la génération d'images.
— Stable Diffusion Web UI
Stable Diffusion Web UI est une interface permettant d'utiliser des modèles d'IA générative open source en local, sur son propre poste, ou à partir d'un autre poste jouant le rôle de serveur.
Les modèles open source peuvent être téléchargés sur Hugging Face, ou d'autres plateformes dédiées (comme CivitaAi, bloqué à l'école) ou les dépôts officiels sur Github. Par exemple les modèles de Stable Diffusion sont accessibles ici : https://github.com/Stability-AI/generative-models
— Lancer un serveur local Stable Diffusion sur le PC de l'école
Sur le PC de la salle 305 est équipé d'une carte graphique Nvidia GeForce RTX 4080 SUPER, assez performante pour la génération. C'est cette machine qui générera les images, mais c'est vous qui lancerez les commandes depuis votre poste, dans l'interface web de Stable Diffusion.

Sur le PC de l'école :
- Branchez le câble réseau
- Créez un point d'accès wifi
- Lancez Stable Diffusion Web UI directement depuis le raccourci bureau
- Ouvrez l'application Invite de commande, écrivez
ipconfiget appuyer sur Entrée. Trouvez l'adresse IP du PC dans le texte (en général : 192.168.X.XX)
Sur votre machine :
- Rejoindre le réseau “wifi_secours” avec le mot de passe *******.
- Dans un navigateur web entrez l’adresse suivante : 192.168.X.XX:7860
Vous vous retrouvez sur l'interface de Stable Diffusion Web UI.
— Texte vers image(s)
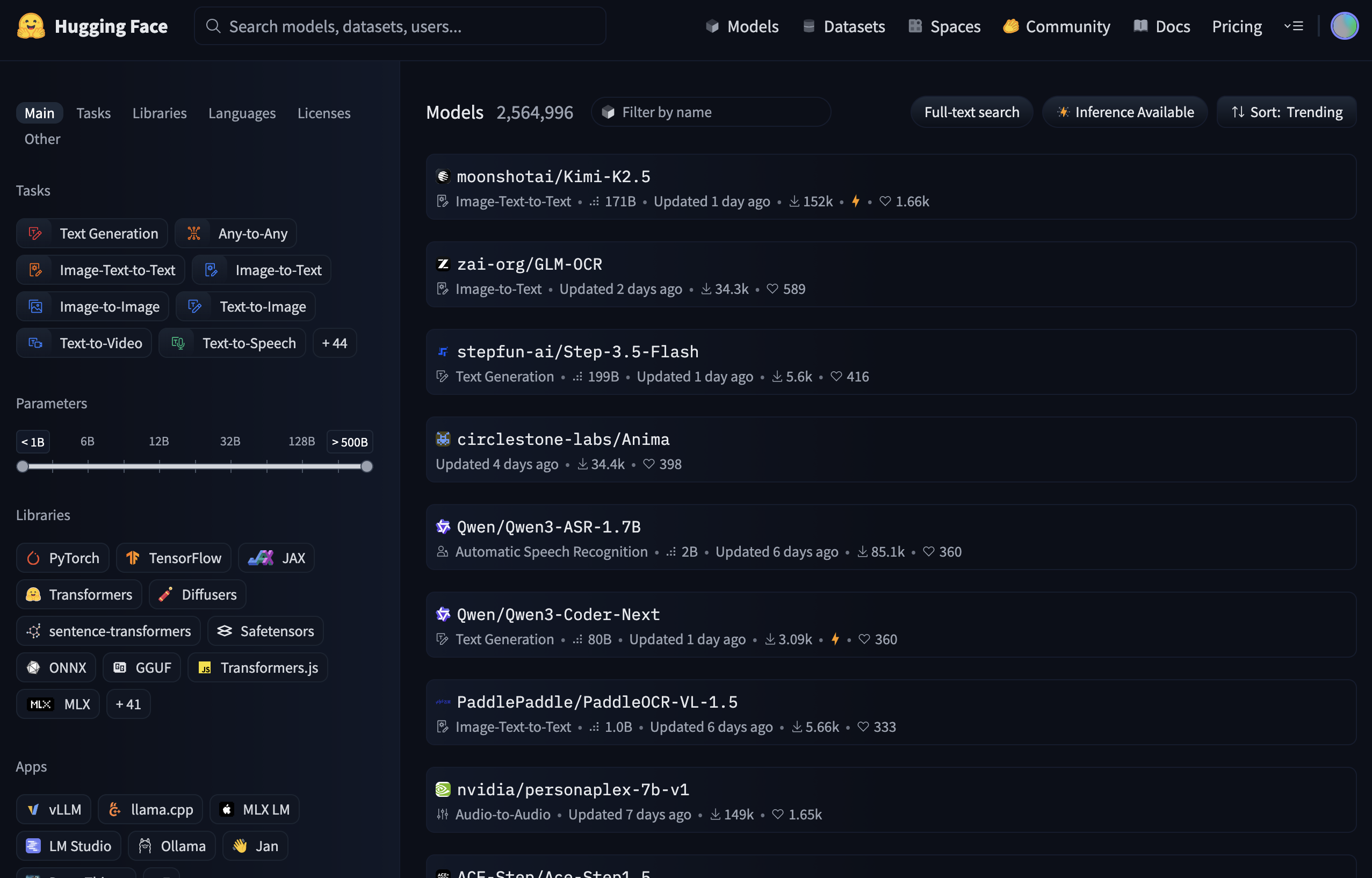
Réglages :
- Choisissez le modèle
sd_xl_turbo. Ce modèle est une variante du modèle SDXL, orienté vers la rapidité de génération. Si vous souhaitez un rendu de haute qualité, mais plus lent, préférez le modèle SDXL de base, ou d'autres modèles comme Flux, Dreamshaper, ou autres. Les réglages seront différents (en général 20-30 steps, 6-8 CFG scale, euler a ou DMP++ Karras pour le sampler, 1024px x 1024px)
Pour le modèl eSDXL Turbo, les réglages sont plus limités :
- Sampling steps : 2-4
- Sampling method : eular a
- CFG scale : 1
- taille 512px x 512px
- Rédigez ou générez un prompt simple, en anglais ou en français, puis cliquez sur Generate
Vous pouvez donner des précisions de style dans le panneau SDXL Styles. Pour cela cochez Enable Style Selector et sélectionnez un style.
Par exemple le prompt basique "Winter landscape" peut être automatiquement complété par une précision de style, ce qui transformera les instructions prompt positif "cinematic photo Winter landscape, 35mm photograph, film, bokeh, professional, 4k, highly detailed", et un prompt négatif : "drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly"
Résultats :


— Image vers image(s)
Les fonctionnlités img2img permettent de contrôler la génération à partir d'une image de référence. Voici un rapide panorama des réglages possibles :
- L'icône 📎 sous le bouton Generate déclenche la fonction Interrogate CLIP qui génère une descirption de l'image. C'est le moyen le plus rapide de créer le prompt nécessaire à la génération
img2img. Attention sur un serveur partagé la description automatique est un peu lente et bloque les autres générations; Préférez la description locale via un LLM comme Ollama ou LM Studio, par exemple avec le modèle Gemma3; - Les options
txt2imgsont toujours présentes :Size,Steps,Seed,CFG Scale. Un nouveau réglage est disponible enimg2img: Denoising strength, qui permet d'ajuster la manière dont la génération colle à l'image (valeurs basses mais > 0,5), ou au prompt (valeurs plus hautes). - L'extension ControlNet (à installer via le panneau Extensions) ajoute des fonctions de contrôle de la génération à partir de la même image ou d'une autre image. Le contrôle de type Depth guide de manière très précise les variations, en analysant soit l'image principale, soit une image de référence.
— Expérimenter
Le travail de génération devient intéressant lorsqu'on met en place des processus de génération plus complexes avec différentes étapes qui articulent contrôle et aléatoire, ou mettent en jeu plusieurs modèles, voire différents outils.
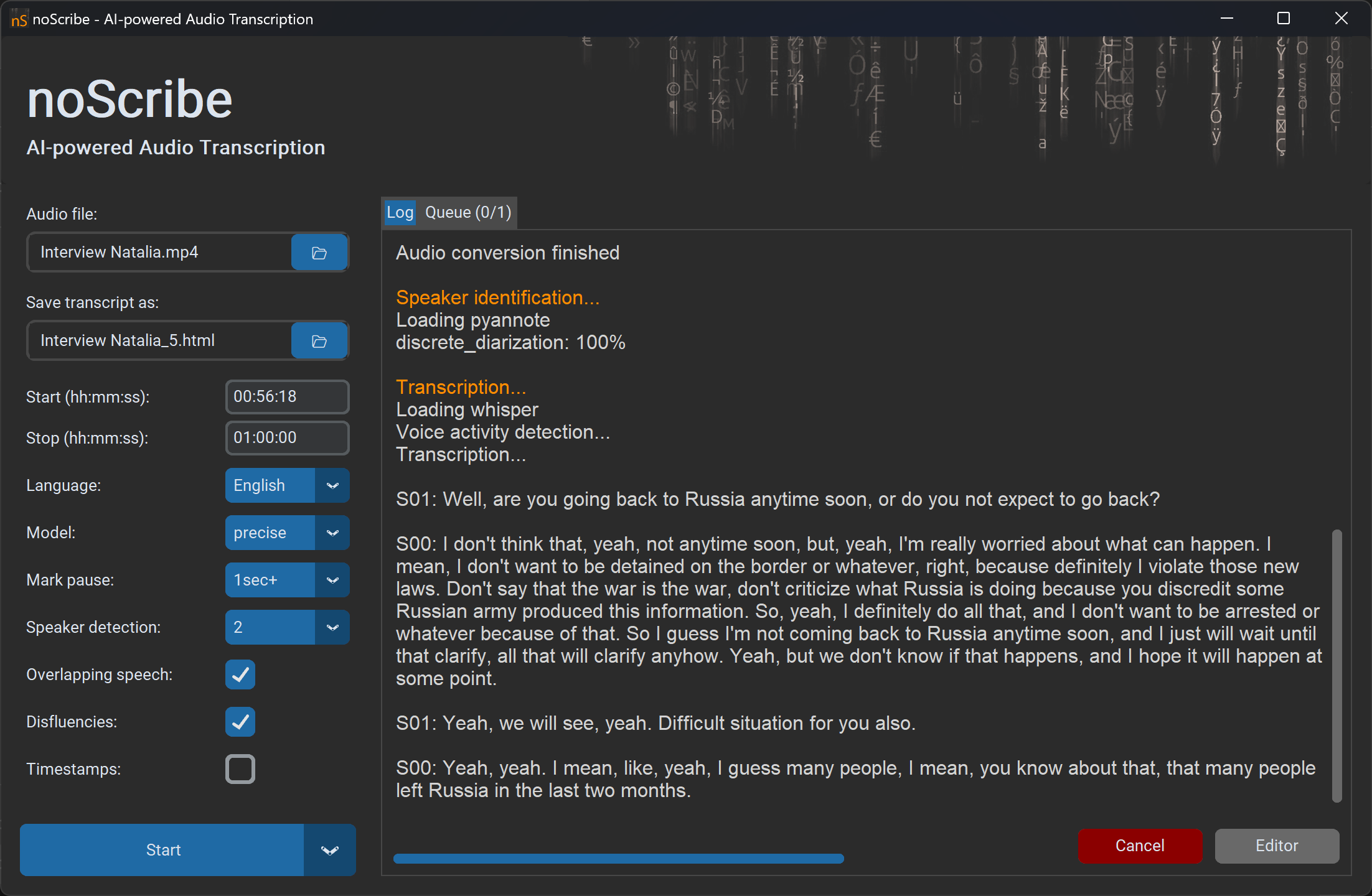
Par exemple pour son projet La ville qui n’existait pas 3: Les veilleurs (2050), Grégory Chatonsky a chaîné différents modèles pour générer des images, vidéos et sons à partir d'archives de cartes postales. Ce schéma décrit le processus qu'il a conçu :